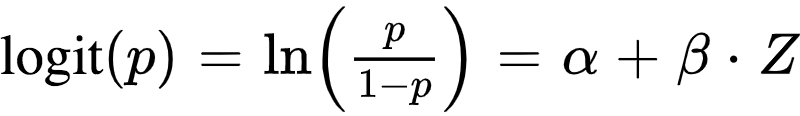
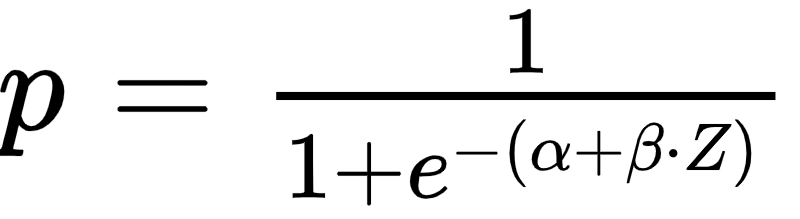
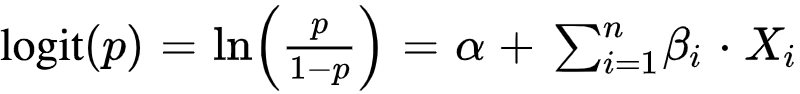
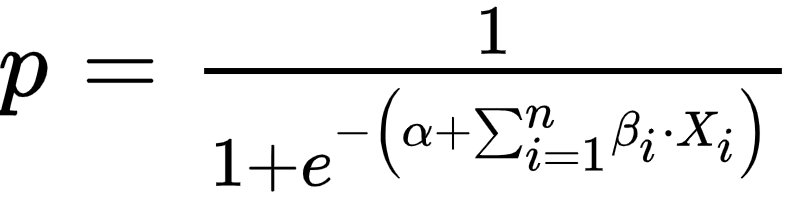
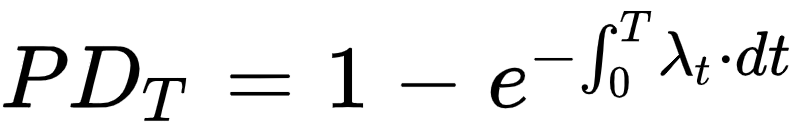
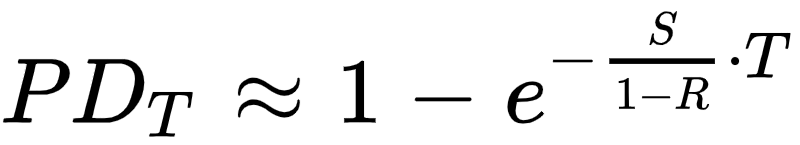
Volatility & Derivatives
In this post we give an introduction to the Heston model which is one of the most used stochastic volatility model. It assumes that the

We will focus here on the probability of default, one of the key measure of credit risk, introducing different ways to measure it.
The probability of default is the likelihood that a borrower, which can be an individual, a corporate or a government fails to meet its debt obligations within a specified time period.
It is a crucial measure for lenders, investors, and financial institutions to assess and manage credit risk.
We will focus here on the probability of default for corporates and governments.
There are different factors influencing the probability of default of a borrower, such as:
There are different ways to assess the probability of default of a company or a government:
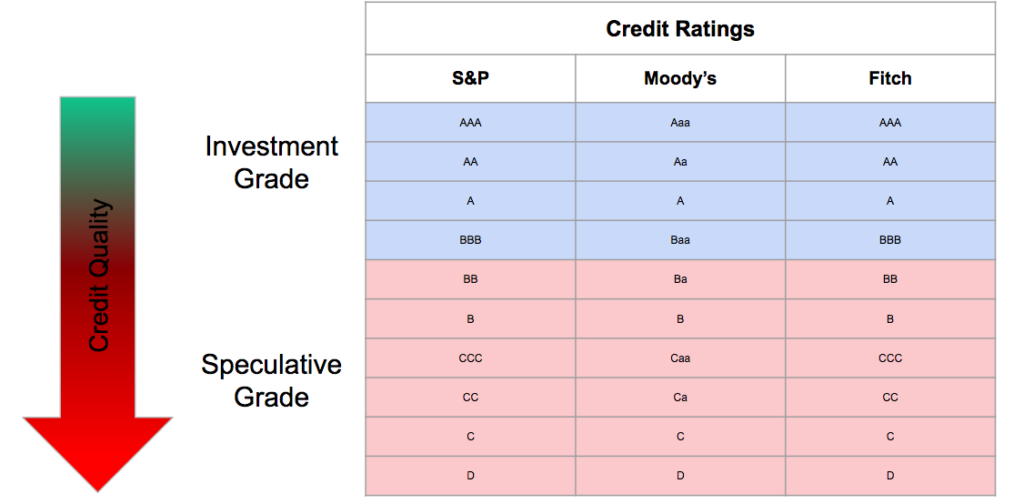
Standard & Poor’s, Moody’s and Fitch are the three major credit rating agencies, all three are American. They mainly rate corporate, financial institutions and countries.
Ratings are from AAA which is the highest rating to D which corresponds to default.
They have a significant impact, influencing borrowing costs and investment decisions.
Investment grades correspond to the highest ratings with the lowest probability of default, while speculative grades are the lowest rating with the highest risk of default.
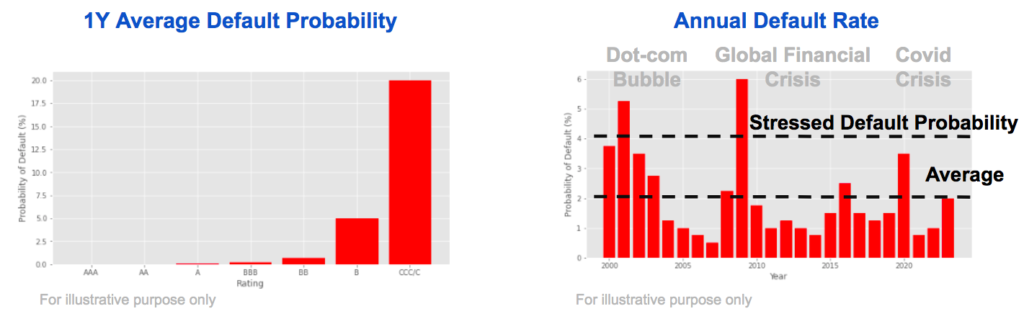
Rating agencies publish statistics on their data including the average default rate through the cycle.
We see that the default probability increases significantly when the credit quality deteriorates.
The default rate varies, with higher default rate during crisis periods, allowing to asset default probability over different phases of the economic cycle.
Numbers here are purely illustrative.
The credit score is a numerical representation of the creditworthiness.
The Altman Z-Score is a famous scoring formula for predicting bankruptcy of corporate, first published in 1968 by Edward I. Altman.
It is mostly accounting based. Here is the original z-score formula for manufacturing companies.
Z = 1.2X1 + 1.4X2 + 3.3X3 + 0.6X4 + 1.0X5
The z-score of a company is a function of five ratios:
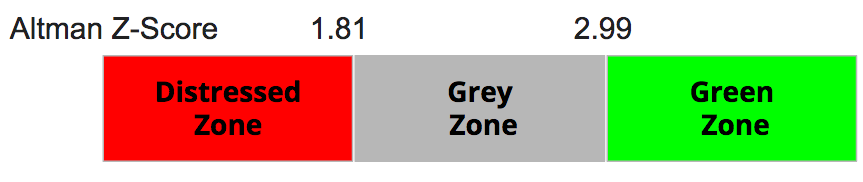
If the z-score is below 1.81 the company is in distressed zone, with a higher risk of failure, while if the z-score is above 2.99 the company is in green zone with a low risk of default. The Grey zone is in-between.
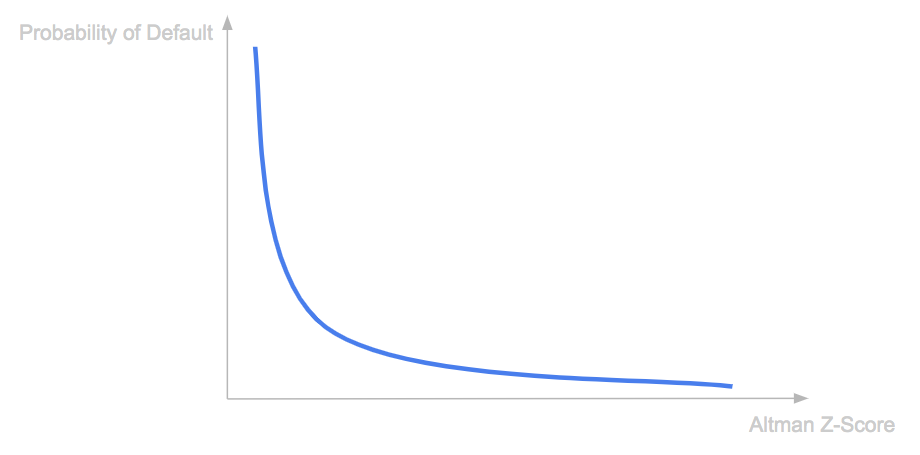
The Z-Score itself does not directly provide a default probability, empirical studies and historical data can help estimate a mapping from Z-Scores to default probabilities.
One approach is to use logistic regression on historical data of companies’ Z-Scores and their subsequent default rates to estimate the probability of default.
First we collect historical data of companies with their Z-Scores and whether they defaulted or not.
Then we fit a logistic regression model and we can estimate the default probability.
Logistic regression can be done as well using a series of financial data (Xi)i=1…n to estimate the default probability.
Exploratory data analysis, variable selection methods can be used to choose the most relevant variables to be included in the regression.
Machine learning classification techniques can be tested as well such as Decision Tree, Random Forests, Gradient Boosting Machines, Support Vector Machines or Neural Network.
In order to estimate default probabilities from market data we need a default model.
There are two main families of default models:
Structural models are accounting based, the total asset of a company is equal to the sum of its equity and its debt.

There is a default if the total asset of the company goes below its debt.
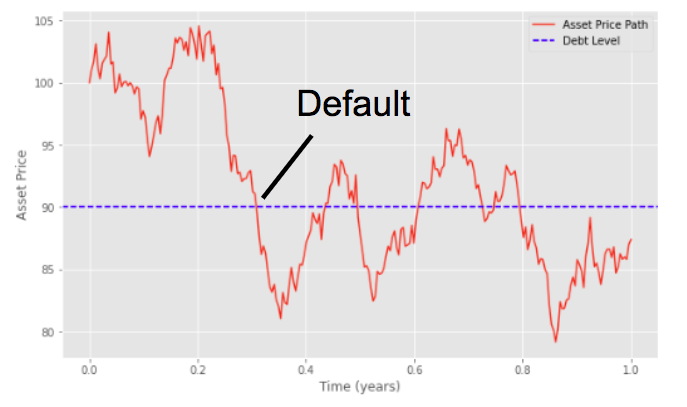
In the Merton Model, the company’s equity is modelled as a call option on its asset, we are in the Black-Scholes framework.
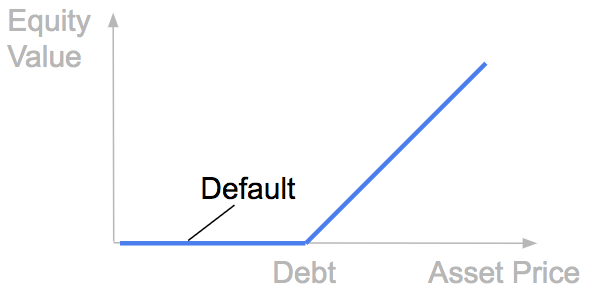
Without going much more into details in this article, in this framework the probability of default is a function of:
PD = f(D, E, σE, T, r)
In reduced form models, defaults occur randomly, the default time is random and is driven by a default intensity process λ, we assume that lambda is deterministic here.
In this framework the default probability before T (PDT) can be expressed as following, it is a function of the integral of λt between 0 and T.
It can be shown that if we assume a constant default intensity λ we have the credit spread S which is very close to the product of lambda and 1 minus the recovery rate:
S ≈ λ x (1 – R)
And so the default probability before T can be directly estimated from the credit spread if we fix the value of the recovery rate.
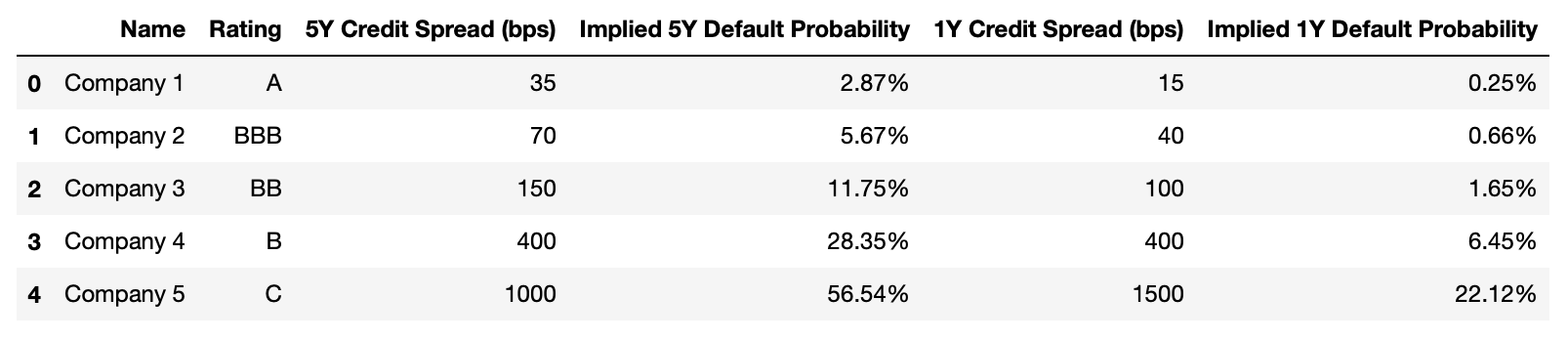
We fix the value of the recovery rate at 40% in the example below, which is the market convention for senior unsecured debts. For these five companies, we assume that we know the 5y credit spread. So we can estimate the five year default probability using the previous formula.
Similarly if we know the value of the 1Y credit spread we can estimate the 1Y default probability.
Credit Risk Modelling: the Default Time Distribution
An Introduction to Reduced-Form Credit Risk Models
Pricing of a Defaultable Bond with a Reduced-Form Model (Part I)
Pricing of a Defaultable Bond with a Reduced-Form Model (Part III, IV, V)
Save 25% on All Quant Next Courses with the Coupon Code: QuantNextBlog25
For students and graduates: We offer a 50% discount on all courses, please contact us if you are interested: contact@quant-next.com
We summarize below quantitative finance training courses proposed by Quant Next. Courses are 100% digital, they are composed of many videos, quizzes, applications and tutorials in Python.
Complete training program:
Options, Pricing, and Risk Management Part I: introduction to derivatives, arbitrage free pricing, Black-Scholes model, option Greeks and risk management.
Options, Pricing, and Risk Management Part II: numerical methods for option pricing (Monte Carlo simulations, finite difference methods), replication and risk management of exotic options.
Options, Pricing, and Risk Management Part III: modelling of the volatility surface, parametric models with a focus on the SVI model, and stochastic volatility models with a focus on the Heston and the SABR models.
A la carte:
Monte Carlo Simulations for Option Pricing: introduction to Monte Carlo simulations, applications to price options, methods to accelerate computation speed (quasi-Monte Carlo, variance reduction, code optimisation).
Finite Difference Methods for Option Pricing: numerical solving of the Black-Scholes equation, focus on the three main methods: explicit, implicit and Crank-Nicolson.
Replication and Risk Management of Exotic Options: dynamic and static replication methods of exotic options with several concrete examples.
Volatility Surface Parameterization: the SVI Model: introduction on the modelling of the volatility surface implied by option prices, focus on the parametric methods, and particularly on the Stochastic Volatility Inspired (SVI) model and some of its extensions.
The SABR Model: deep dive on on the SABR (Stochastic Alpha Beta Rho) model, one popular stochastic volatility model developed to model the dynamic of the forward price and to price options.
The Heston Model for Option Pricing: deep dive on the Heston model, one of the most popular stochastic volatility model for the pricing of options.
In this post we give an introduction to the Heston model which is one of the most used stochastic volatility model. It assumes that the

In the previous post (link) dedicated to the pricing of defaultable bonds with a reduced form model, we saw how to price a zero coupon
The Merton Jump Diffusion (MJD) model was introduced in a previous article (link). It is an extension of the Black-Scholes model adding a jump part